
NVIDIA udostępnia pakiet CUDA 5 (Video)

Firma NVIDIA udostępniła pakiet programistyczny NVIDIA CUDA 5 w wersji finalnej. Jest to nowa wersja najpopularniejszej platformy do tworzenia oprogramowania wykorzystującego obliczenia równoległe, a także do akceleracji aplikacji naukowych i technicznych za pomocą procesorów graficznych. Pakiet można pobrać za darmo ze strony internetowej NVIDIA Developer Zone.
Platforma CUDA została do tej pory pobrana 1,5 miliona razy i obsługuje ponad 180 wiodących aplikacji – naukowych, technicznych i komercyjnych. Model programowania CUDA jest najpopularniejszym rozwiązaniem dla programistów pragnących wykorzystać akcelerację obliczeń z wykorzystaniem procesorów graficznych w tworzonych projektach.
Bazując na tym sukcesie, firma NVIDIA stworzyła piątą wersję platformy CUDA, dzięki której programowanie aplikacji przyśpieszanych przez procesory graficzne staje się szybsze i łatwiejsze niż kiedykolwiek. Nowy pakiet obsługuje funkcje dynamicznych obliczeń równoległych, biblioteki wywoływane przez procesory graficzne, technologię NVIDIA GPUDirect™ dla RDMA (zdalnego i bezpośredniego dostępu do pamięci), a także zawiera zintegrowane środowisko programistyczne (IDE) NVIDIA Nsight™ Eclipse Edition.
Nowe funkcje pakietu CUDA 5
CUDA 5 zapewnia programistom możliwość pełnego wykorzystania mocy kart graficznych NVIDIA, w tym akceleratorów wykorzystujących procesory graficzne oparte na architekturze obliczeniowej NVIDIA Kepler™ – najszybszej, najwydajniejszej i najsprawniejszej architekturze, jaką kiedykolwiek stworzono. Najważniejsze funkcje nowej platformy to:
Dynamiczne przetwarzanie równoległe – akceleracja nowych algorytmów na procesorach graficznych
Wątki uruchomione na procesorach graficznych mogą dynamicznie tworzyć następne nowe wątki, umożliwiając procesorowi graficznemu dostosowanie się do danych. Funkcja dynamicznego przetwarzania równoległego minimalizuje ilość przesyłanych danych między procesorem graficznym a procesorem centralnym, znacznie upraszczając programowanie równoległe. Opisywana funkcja umożliwia też akcelerowanie szerszego zestawu popularnych algorytmów na procesorach graficznych, stosowanych w aplikacjach wykorzystujących adaptacyjne siatki numeryczne i obliczenia dynamiki płynów.
Biblioteki wywoływane przez procesor graficzny – możliwość stworzenia zewnętrznego ekosystemu
Nowa biblioteka CUDA BLAS umożliwia programistom wykorzystywanie funkcji dynamicznego przetwarzania równoległego we własnych bibliotekach wywoływanych przez procesor graficzny. Programiści mogą tworzyć wtyczki interfejsów programistycznych (API), które mogą służyć do rozbudowy funkcjonalności jąder, umożliwiając wdrożenie wywołań zwrotnych na procesorze graficznym i dostosowanie funkcjonalności zewnętrznych bibliotek wywoływanych przez procesor graficzny. Funkcja „łączenia obiektów” zapewnia wydajny i dobrze znany proces tworzenia dużych aplikacji dla procesorów graficznych, umożliwiając kompilowanie wielu plików źródłowych platformy CUDA do kilku oddzielnych plików obiektów i łączenie ich z większymi aplikacjami oraz bibliotekami.
Obsługa technologii GPUDirect dla RDMA – minimalizuje wąskie gardła w pamięci systemu
Technologia GPUDirect pozwala na nawiązanie bezpośredniej komunikacji pomiędzy procesorami graficznymi i innymi urządzeniami PCI-E, zapewniając bezpośredni dostęp do pamięci kartom interfejsów sieciowych i kartom graficznym. GPUDirect znacząco zmniejsza również opóźnienie działania polecenia MPISendRecv między poszczególnymi węzłami procesorów graficznych w klastrze, a w konsekwencji zwiększa ogólną wydajność aplikacji.
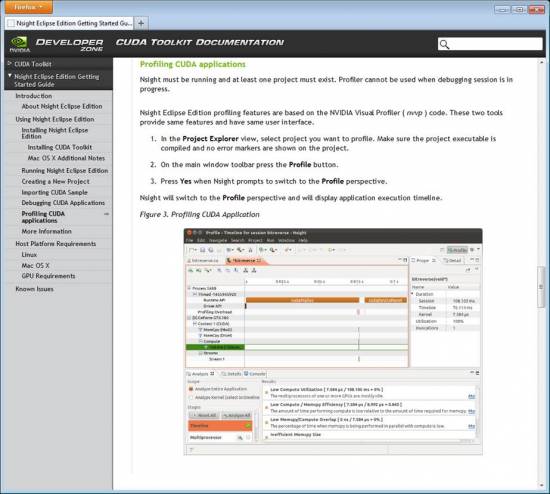
NVIDIA Nsight Eclipse Edition – szybkość i łatwość generowania kodu CUDA
NVIDIA Nsight Eclipse Edition umożliwia programowanie, debugowanie i profilowanie aplikacji wykorzystujących procesory graficzne w popularnym interfejsie IDE opartym na Eclipse, przeznaczonym dla systemów Linux i Mac OS X. Zintegrowany edytor języka CUDA i próbki kodu CUDA przyśpieszają generowanie własnego kodu aplikacji CUDA, a funkcja automatycznej refaktoryzacji kodu umożliwia łatwe przenoszenie pętli wykorzystujących procesory centralne do jądra CUDA. Zintegrowany, zaawansowany system analizy zawiera narzędzia do automatycznego sprawdzania wydajności, a także przewodnik, za pomocą którego programista może naprawić wąskie gardła w kodzie, wykonując odpowiednie czynności krok po kroku. Funkcja wyróżniania składni pozwoli z łatwością odróżnić kod przeznaczony dla procesorów graficznych od kodu dla procesorów centralnych.
Nowe internetowe centrum zasobów CUDA
Aby pomóc programistom w jak najlepszym wykorzystaniu potencjału obliczeń równoległych realizowanych za pomocą technologii CUDA, firma NVIDIA stworzyła bezpłatne internetowe centrum zasobów dla programistów CUDA, dostępne pod adresem http://docs.nvidia.com. Witryna zawiera najnowsze informacje na temat platformy CUDA i powiązanego z nią modelu programistycznego, a także zapewnia dostęp do pełnej dokumentacji CUDA i technologii, w tym narzędzi, próbek kodu, bibliotek, interfejsów aplikacji i przewodników dotyczących optymalizowania i programowania aplikacji.

Aktualizuj sterowniki Nvidia Quadro do wersji v340.66

Platforma CUDA 6 firmy NVIDIA znacząco upraszcza programowanie równoległe

MSC Software wykorzystuje procesory graficzne NVIDIA

Uniwersytet Oksfordzki uruchamia najpotężniejszy superkomputer w Wielkiej Brytanii oparty na procesorach graficznych

NVIDIA udostępnia społeczności otwartego oprogramowania kompilator oparty o architekturę CUDA

Nowa wersja platformy CUDA przyśpiesza oraz ułatwia badania naukowe.


SOLIDWORKS 2025 - kluczowe funkcje

Aktualizacja AutoCAD i AutoCAD LT 2025.1

Nowe polecenie w NX do zaokrąglania krzywych na powierzchni
Rzutowanie krzywej w SOLIDWORKS

BenQ SW242Q - profesjonalny 24 calowy monitor IPS 2K

Zmiany w licencjonowaniu produktów Autodesk

Udoskonalone działanie grafiki w SOLIDWORKS

Dassault Systemes i Mistral AI zaczynają współpracę









